
Introduction
Characterising multimedia content with relevant, reliable and discriminating tags is vital for multimedia information retrieval. With the rapid expansion of digital multimedia content, alternative methods to the existing explicit tagging are needed to enrich the pool of tagged content. Currently, social media websites encourage users to tag their content. However, the users’ intent when tagging multimedia content does not always match the information retrieval goals. A large portion of user defined tags are either motivated by increasing the popularity and reputation of a user in an online com-munity or based on individual and egoistic judgments. Moreover, users do not evaluate media content on the same criteria. Some might tag multimedia content with words to express their emotion while others might use tags to describe the content. For example, a picture receive different tags based on the objects in the image, the camera by which the picture was taken or the emotion a user felt looking at the picture.
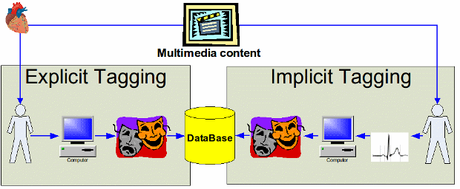
The principle of implicit tagging is to replace the user input by automatically finding descriptive tags for multimedia content, derived from an observer’s natural response. For instance, the emotions someone shows. An overview of this difference with explicit tagging is illustrated in the diagram above.
In order to facilitate research on this new area of multimedia tagging, we have recorded a database of user responses to multimedia content.
Database Content
30 participants were shown fragments of movies and pictures, while monitoring them with 6 video cameras, a head-worn microphone, an eye gaze tracker, as well as physiological sensors measuring ECG, EEG (32 channels), respiration amplitude, and skin temperature.
Each experiment consisted of two parts. In the first part, fragments of movies were shown, and a participant was asked to annotate their own emotive state after each fragment on a scale of valence and arousal, as shown to the right.
In the second part of the experiment, images or video fragments were shown together with a tag at the bottom of the screen. In some cases, the tag correctly described something about the situation. However, in other cases the tag did not actually apply to the media item. Below are two examples, overlayed with the eye tracking measurements as red dots and lines for gaze locations and shifts, respectively.


After each item, a participant was asked to press a green button if they agreed with the tag being applicable to the media item, or press a red button if not.
During the whole experiment, audio, video, gaze data and physiological data were recorded simultaneously with accurate synchronisation between sensors. The database is freely available to the research community.